Are AI Systems Incompatible with Data Privacy?
Paul Bouchaud, Pedro Ramaciotti / Mar 16, 2026
Who we vote for, who we love, what we believe in — across continents and legal traditions, a shared conviction holds that these characteristics deserve special protection. In Europe, this principle is enshrined in the General Data Protection Regulation: Article 9 prohibits the processing of sensitive personal data — including political opinions, religious beliefs, sexual orientation, and biometric data — unless narrow exceptions apply.
These protections were designed for a world in which sensitive data had to be actively collected. But what happens when AI systems infer sensitive characteristics without ever being asked to do so?
Recent evidence suggests that AI systems designed to predict user behavior inevitably learn to represent and leverage political opinions and other sensitive data categories — because online behavior reflects personal beliefs that sufficiently powerful models can infer and exploit. This blurs the boundary between deliberate and inadvertent political profiling. In this article, we explore this boundary along a continuum. At one end, platforms explicitly classify users into political or religious categories; at the other, recommendation algorithms and conversational bots silently encode ideology into user profiles as a byproduct of optimizing for engagement or text processing. Between these extremes lie systems that must infer each user's political position to function at all.
The social media platform X provides a stark illustration of these systems — not necessarily because it is uniquely problematic, but because past transparency initiatives allow us to peer inside the black box. We analyze four algorithmic systems operating within X, each occupying a different position along this continuum (see Figure).

Figure
Taken together, these systems expose a fundamental tension: the law protects sensitive information such as ethnicity, sexual orientation, and political opinions, yet AI systems with access to rich behavioral traces — what we read, like, share, and who we talk to — can reconstruct precisely this information. Advances in AI explainability now make it possible to identify which internal variables inside these models correspond to political opinions and other protected categories, eroding the line between active and passive profiling to the point where claiming ignorance becomes untenable.
X ads
At the most explicit end of the continuum lies X's advertising system. In June 2025, AI Forensics revealed that X allowed advertisers to target — or exclude — users based on protected characteristics. For instance, TotalEnergies (one of France’s main energy providers), excluded users interested in Green party politicians and "kosher" products from its ad targeting on the platform; Dell excluded users engaging with content labeled "#lesbian"; the European Commission itself excluded political affiliations from its ads targeting users, which were identified with labels such as "fascist" and "communist” that were provided by X.
By deliberately classifying users into categories that directly map onto political opinions, sexual orientation, and religious beliefs (in the form of labels available to advertisers), this system appears to violate both GDPR Article 9(1) and Article 26(3) of the Digital Services Act, which explicitly prohibits ad targeting based on sensitive data categories. Nine NGOs have since filed complaints with national Digital Services Coordinators. This represents the clearest case of active profiling — and the most straightforward to remedy: removing sensitive category labels from the advertising system entirely.
Crowd-sourced moderation
Moving along the continuum illustrates why solutions to prevent profiling on sensitive attributes may not always be as direct. Community Notes is X's crowdsourced moderation system: regular users submit fact-checking notes, and an algorithm in X selects those "found subjectively helpful by individuals from diverse viewpoints." To do this, the system must infer where each user stands on an ideological scale — not from what users declare, but automatically inferred from how they rate others' notes.
As we corroborated empirically across 13 countries in five continents, the system models each rater's "viewpoint" from past rating patterns into internal ideology scales that map onto traditional political survey scales. This political spectrum was not hardcoded — it emerged from the data as the dimension that best predicts which users agree with which notes. The algorithm's parameters are deliberately set to make the model rely primarily on these learned ideological positions, which align closely with users' actual political leanings. The system infers political opinion from behavior not as a side effect, but as the mechanism specified by creators and required for it to function.
The implications extend well beyond X. Meta, YouTube, and TikTok have all announced or deployed their own Community Notes systems. Any implementation that relies on "bridging" consensus across political divides must, by design, first determine where each user stands politically. What began as one platform's experiment is becoming industry infrastructure — and with it, the systematic inference of political opinion at scale.
Whatever the benefits for content moderation — and our results show Community Notes have important limitations — such systems are fundamentally at odds with data privacy laws because they compute the ideological positions of millions of users without explicit consent. Compliance would still require clear actions in this case: either obtaining informed consent from participants, or abandoning these systems altogether.
Recommender systems
Further along the continuum, toward passive profiling, the latest scientific results reveal a more fundamental tension between AI and data privacy.
Recommender systems — such as X's "Who to Follow" contact recommendation and timeline algorithms — sit at the heart of social platforms' economic models. These systems convert users and content into numerical profiles that capture similarity and relevance, determining what each person sees.
By analyzing X's code alongside data gathered from users, we were able to reverse-engineer how it decides who to recommend. Within the model's internal “view of the world”, we identified a direction that reproduces users' Left-Right ideology positions. This political dimension coexists alongside others capturing age, gender, and topic interests (such as interest in new or sports), but cannot be reduced to them — it is not a proxy for any combination of socio-demographic variables that would constitute valid grounds for processing.
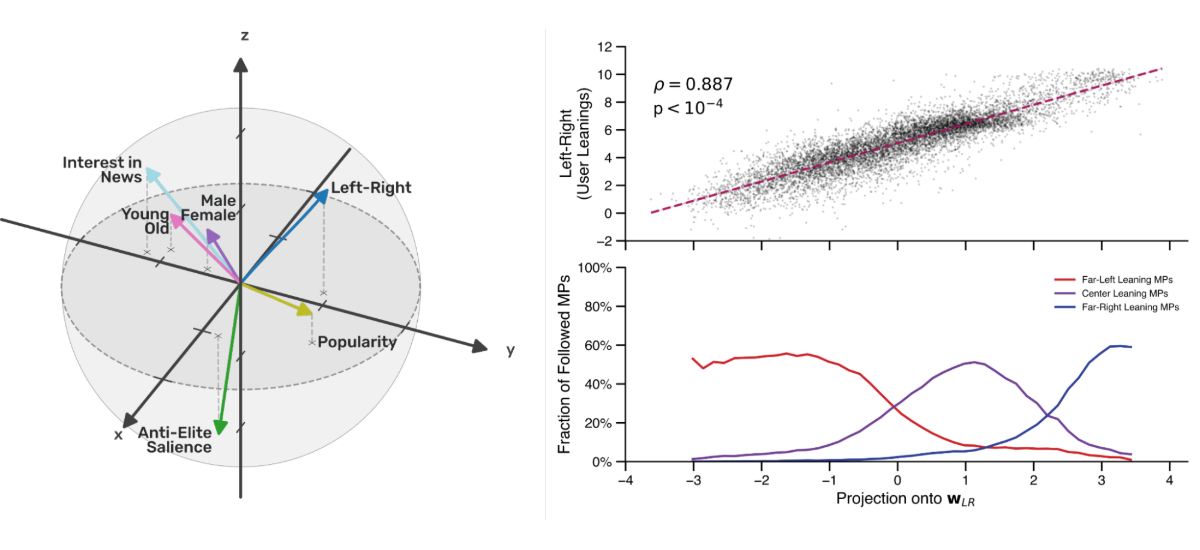
Directions in AI representation space correlating with various user attributes (left), and their correlation with Left-Right ideology inferred with political surveys (top right) and compared to how users follow Members of Parliament from Left-, Centrist-, and Right-leaning parties (bottom right).
Crucially, the system does not store "this user is conservative" explicitly. Platform engineers have not, for all we know (and in contrast with systems such as Community Notes), specified political profiling as an objective. Instead, the algorithm learns from engagement patterns, follower networks, and response behaviors that correlate with political orientation, and leverages those patterns to determine personalized recommendations. This is passive but systematic profiling: political opinions structure online behavior so fundamentally that most effective contemporary models would capture them.
The problem becomes acute when explainability tools reveal what these systems are actually computing. Once it is possible to identify which internal variables correspond to political opinion, claiming ignorance of the profiling taking place inside one's own systems becomes untenable. Failing to regulate this form of profiling amounts to authorizing platforms to knowingly use political dimensions — for hundreds of millions of users — in the computation of contact, ad, and content recommendations.
Conversational AI
Finally, At the far end of the spectrum between passive and active profiling lie large language models. We recently showed that models (such as GPT-5, but also others) process and leverage sociodemographic profiles inferred from implicit conversational cues: revealing your name triggers these systems to produce an implicit inference of your ethnicity, disclosing the sports you practice triggers the model to infer your gender. We also show that these hidden inferences have concrete downstream effects, and may affect, for instance, the recommendations you receive related to your career advancement (someone doing ballet will more likely than one doing wrestling be recommended to become a nurse rather than a doctor).
This passive personalization emerging by virtue of deep statistical correlations in training data can be pushed further when platform providers use prompt engineering to actively solicit protected information — as with Grok's "romance" persona, whose system prompt explicitly instructs the model to determine the user's sexual orientation. This crosses from algorithmic inference to direct solicitation of Article 9 special category data.
A fundamental tension between AI and privacy
Viewed through GDPR’s Article 9, the implications are stark. The regulation does not distinguish between "directly collected" and "algorithmically inferred" sensitive data — it forbids the "processing of personal data revealing" sensitive attributes. The Court of Justice of the European Union has confirmed that any data "liable indirectly to reveal sensitive information [...] following an intellectual operation involving deduction or cross-referencing" falls under this prohibition.
Applied consistently, each system along the continuum violates GDPR (and similar national regulations outside the EU). The advertising system targets users based on special category data without explicit consent. Community Notes infers and processes political opinions as the very mechanism determining which content users see. Recommendation algorithms encode political orientation into user profiles that drive content distribution — precisely the "intellectual operation" the Court described. Conversational AI compounds these issues by inferring sensitive characteristics from implicit cues and, in some configurations, actively soliciting them.
The cases nearest to active profiling — ad labels and Community Notes — arise from design choices and could, in principle, be remedied. But the passive cases pose a deeper problem. X's recommender systems encode political ideology not because engineers specified it, but because political opinion structures online behavior so fundamentally that any model optimized for engagement will capture it. This is not a bug specific to one platform — it is a property of sufficiently powerful AI systems trained on human behavioral data.
This creates a regulatory double bind. If passive profiling falls outside GDPR's scope, companies can exploit their systems' latent political dimensions — using explainability tools to identify which variables correspond to ideology, then leveraging them for targeting — while claiming they never actively profiled anyone. If passive profiling falls within scope, a vast family of AI systems becomes non-compliant, creating legal uncertainty.
A path forward: making AI blind to sensitive categories
The same explainability methods that expose this tension also point toward a solution. After identifying the direction in X's representation space that correlates with Left-Right ideology, we surgically removed it — eliminating actionable political opinion information from the system. This intervention increased political diversity in contact recommendations without degrading relevance.
Our approach relied on ideology positions inferred for a large number of users, something platforms could hardly replicate without themselves violating GDPR. But the principle could be applied during training itself, by constraining the model so that it cannot predict the political leaning of known anchors — public political figures or parties — in a way that is fully compliant with privacy laws and requires no inference of ordinary users' ideology.
In a world where AI systems build sufficiently sophisticated models of behavior, and where explainability tools dissolve the line between active and passive profiling beyond plausible deniability, it may not be possible to reconcile AI with data privacy without actively constraining what these systems are allowed to learn.

Authors


