Looking Beyond the Black Box: Transparency and Foundation Models
Prithvi Iyer / Oct 24, 2023Prithvi Iyer is Program Manager at Tech Policy Press.

Foundation models like LLaMA and DALL-E 3 have garnered substantial commercial investment and public attention due to their role in various generative AI applications. However, a significant issue looms over their use: the lack of transparency in how these models are developed and deployed. Transparency is vital for ensuring public accountability, fostering scientific progress, and enabling effective governance of digital technologies. Without sufficient transparency, it's challenging for stakeholders to evaluate these foundation models, their societal impact, and their role in our lives.
This lack of transparency around foundation models mirrors the opacity of social media platforms. Past social media scandals, such as the Rohingya crisis in Myanmar and the Cambridge Analytica scandal in the United States, highlight the social costs associated with a lack of transparency in content moderation and data sharing by the platforms. To prevent similar crises with generative AI, it's crucial that tech companies prioritize transparency. Transparency is critical to digital technologies like AI because most lay persons do not understand what it is or how it actually works.
Researchers from Stanford, Harvard, and Princeton have published a paper titled “The Foundation Model Transparency Index (FMTI)” to address this pressing issue. This index serves as a resource for governments and civil society organizations to hold AI companies to account, and also to provide model developers with tangible steps to improve model transparency. The goal is to ensure that these emerging technologies comply with ethical standards and minimize societal harm.
What does this Index mean and how is it used?
The Foundation Model Transparency Index (FMTI) is a composite index that measures a “complex construct (e.g. transparency) as the basis for scoring/ranking entities (e.g. foundation model developers) by aggregating many low-level quantifiable indicators of transparency.” The index breaks down “transparency” into three domains: (See figure 1)
- Upstream: A set of 32 indicators that identify the “ingredients and processes involved in building a foundation model.” These include labor, data access and computational resources used to train a model.
- Model: A set of indicators that identify the “properties and function of the foundation model.” These include analyzing the capabilities, risks and limitations of the model.
- Downstream: A set of 35 indicators that assess the impact of deploying these foundation models on society. These subdomains cover various aspects such as distribution channels, usage policies and impact on specific geographies.
Figure 1
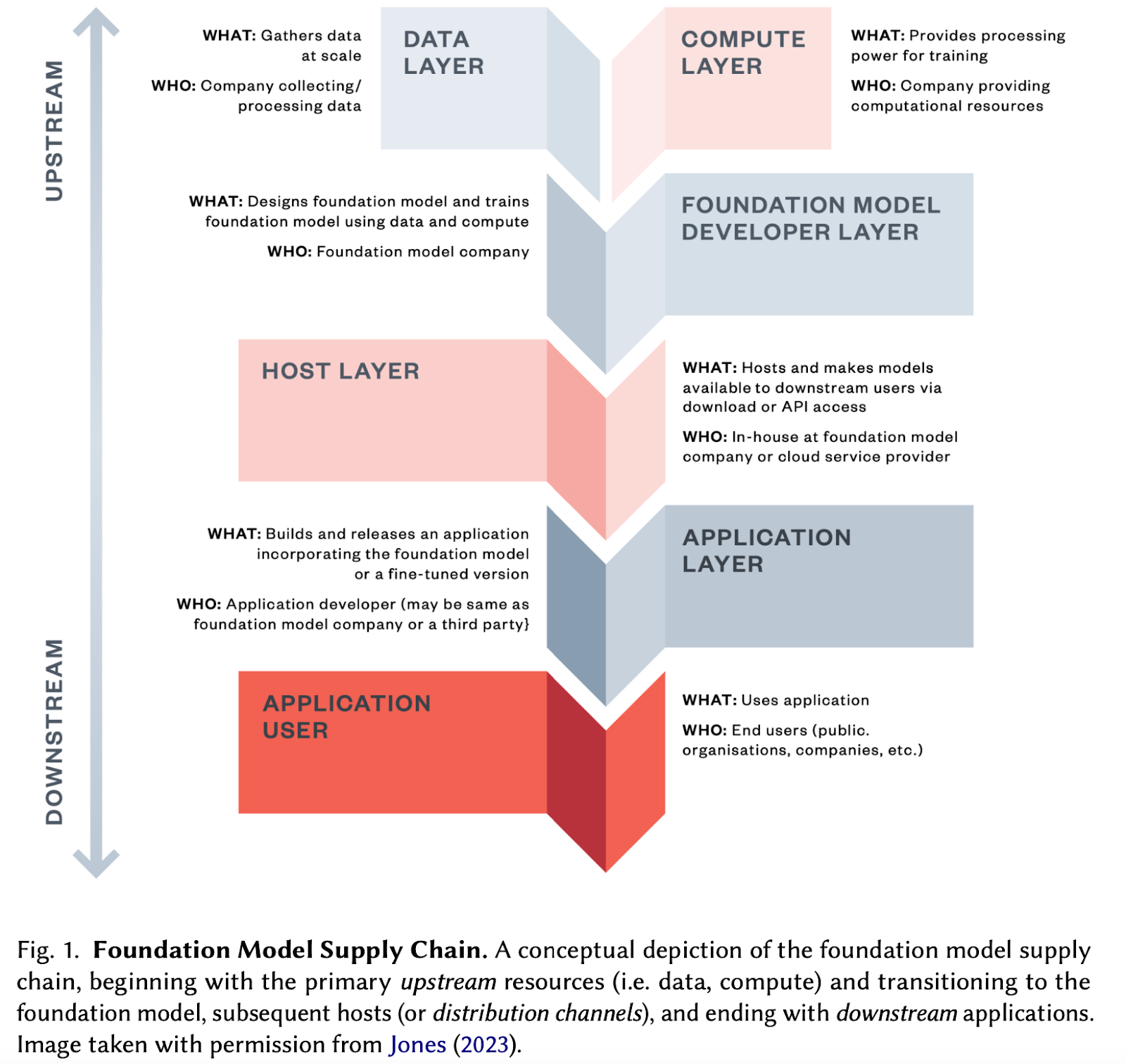
The researchers scored the flagship models of 10 developers (eg. Meta, Google, OpenAI), assessing each indicator on the basis of publicly-available information to make findings reproducible and encourage transparency.
Findings
Applying this transparency index to 10 model developers revealed that there is significant room for improvement across the boardand the overall transparency protocols across different platforms is not uniform. Meta’s foundation model scored the highest (54 out of 100) while Amazon scored the lowest (12 out of 100). The mean score of 37 for all developers indicates an industry struggling to open its doors to scrutiny.
The domain specific findings show that developers score the least for upstream indicators, meaning that transparency around data sharing, data access and labor are very low, with companies like Amazon, Inflection and AI21 labs scoring 0 on all 32 upstream indicators. The lack of transparency around use of labor in training models is consistent with prior research documenting the widespread ethical challenges with data labor. Alarmingly, no company scores points for transparency around data creators, data licensing and copyright mitigations. The industry wide secrecy on these issues relates to societal fears around copyright infringement and intellectual property disputes which are currently under litigation.
In comparison, companies are more transparent about the capabilities of their models, but fall short when it comes to acknowledging limitations, evaluating potential harms, and providing external assessments of mitigation efficacy. Companies are also extremely secretive about basic information like model size or rationale behind release decisions. Thus, a pattern of selective transparency is evident and it is crucial that developers are encouraged to be equally transparent about harms as they are about the model’s capabilities.
Similar to a lack of transparency on how models are built, companies are totally opaque on the downstream impacts of their foundation models. Developers provide no information about impact on market sectors, individuals, geographies, or usage reporting. In the Impact subdomain, the average score hits rock bottom at 11%, with only a meager three developers providing minimal information about downstream applications and no avenue for users to seek redress.
Finally, the researchers look at how transparency differs for open source vs closed source models and find that open source developers who share model weights and code are significantly better with upstream transparency, with an average score of 53% compared to 9% for closed models. However, on downstream impacts, the differences are marginal. The main takeaway is that overall transparency is lacking, especially in the realm of upstream indicators and downstream impacts. The transparency index scores by domain are provided in the figure below:-
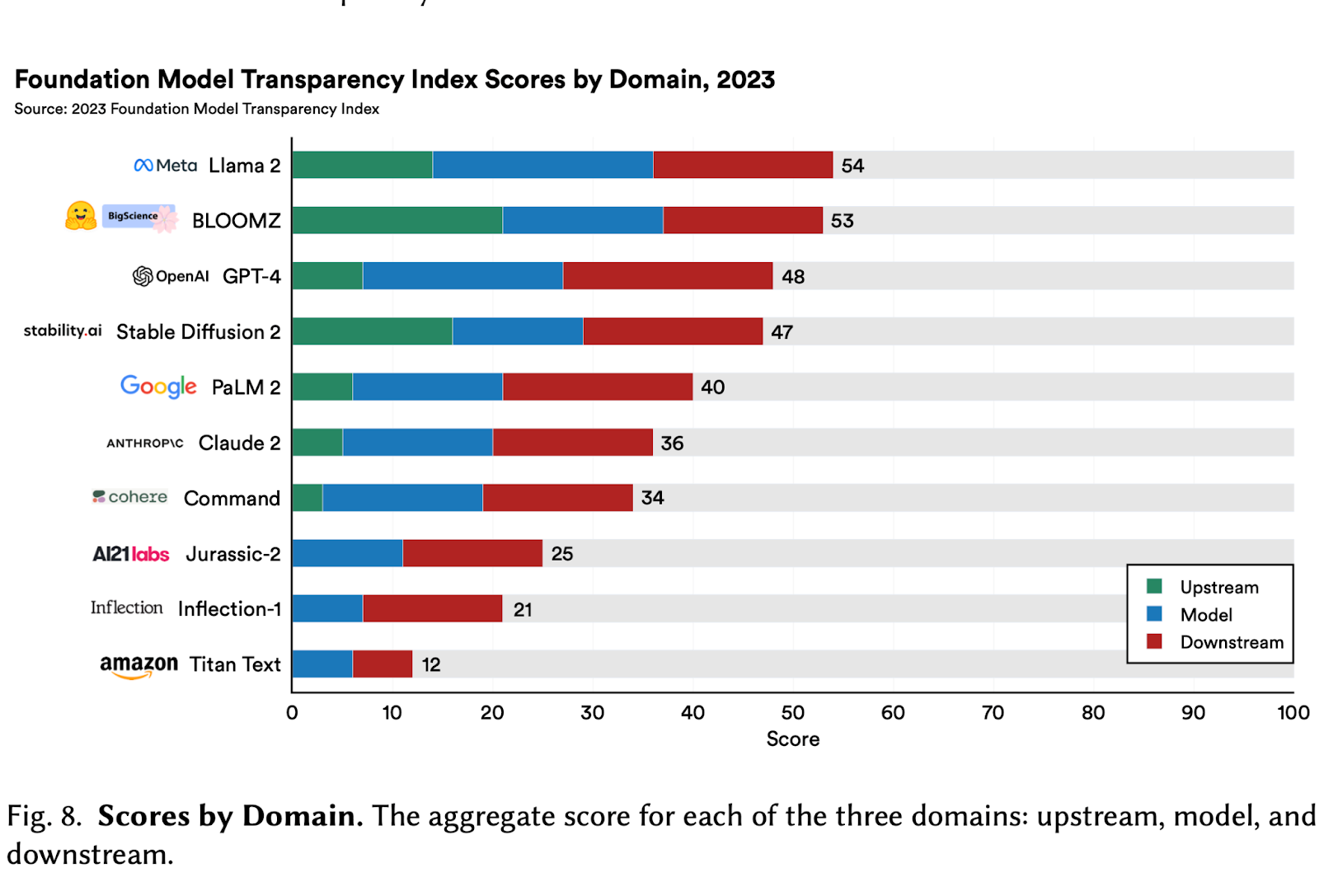
Thus, developers need to be more accountable for how their models are created and its societal impact. Based on these findings, the researchers offer a set of concrete policy recommendations:-
- Deployers of foundation models should push for greater transparency from developers. Since developers earn most of their revenue from the downstream use cases of their models, deployers have the negotiating leverage to demand greater transparency.
- Policymakers should use this index to have more “precise” demands for transparency. A big issue with advocating for greater transparency is that the term is vague and too expansive. This index has provided various subcategories of transparency and policymakers should use this taxonomy to be specific about where they want greater transparency and why. This can help keep tech companies to account and ensure that transparency measures are not merely lip service.
The Way Forward
So what does this transparency index mean for the future of foundation model development and deployment? The efficacy of this research depends on the extent to which tech companies, which are not the best judges of the risks they create, acknowledge and respond to these findings.
Kevin Klyman, a researcher at the Stanford Institute of Human Centered AI and a lead researcher on this project, told Tech Policy Press he is hopeful the index will lead to change.
“We hope that companies will share more information with the public about the real-world impact of their most powerful AI systems,” said Klyman.
On the question of the project’s larger contribution to the AI safety ecosystem, he noted that policymakers need more information on how systems such as large language models function in order to craft better regulations. "Our index tries to aggregate the information that does exist and highlight the gaping holes in the public’s understanding of the development and use of this technology.”
The FMTI joins other projects underway to develop evaluation criteria for AI systems, such as the preliminary standards for generative AI developed by the watchdog group Ranking Digital Rights, which routinely publishes a corporate accountability index and a Big Tech scorecard that evaluates tech companies and their commitments to human rights and other values. Time will tell if these efforts will have the desired impact.
Authors

