
When Federal Agencies Pick AI Vendors, They Are Buying Different Policy Interpretations
Paulo Carvão, Isabel Adler, Jeffrey Zhou, Claudio Mayrink Verdun / May 11, 2026
Seeing More — Seeing Less by Anna Riepe & FARI / Better Images of AI / CC by 4.0
If you are an OpenAI employee, you had an unusual view from your office this March: protesters in robot masks holding a “NO WAR STOP AI” sign and urging employees to quit. The protest captured the most dramatic fear about AI and the Pentagon, the use of AI with autonomous weapons, in battlefield decisions, and surveillance of American citizens.
But most government uses of these tools are likely to look more mundane. Agencies may use AI to summarize long documents, compare proposals, review comments, flag compliance issues, or help staff make sense of complex policy texts. Those uses sound administrative, but they still matter. When an agency changes AI vendors, it may also change what the system notices, downplays, or misses.
Take the Biden administration’s Framework for Artificial Intelligence Diffusion, the sweeping rule governing which countries can access the most powerful American AI systems, revoked by the Trump administration. If you ask ChatGPT, Claude, and Grok what this policy is about, on its face, the three chatbots agree: it is a national security document. The differences appear when you ask a more demanding question, the kind a trained policy analyst would ask. When we gave each model a detailed analytical checklist, ChatGPT and Claude identified cybersecurity safeguards, compliance requirements, and audit mechanisms embedded in the document that shape how it functions in practice. Grok, presented with the same checklist, still saw an export control document primarily. The safety and oversight provisions were invisible.
The finding comes from a broader study that compared commercial LLMs against a rubric-calibrated policy analysis framework across five dimensions: national security, safety and security, civil and human rights, antitrust, and economic resilience. That does not mean each model has a permanent worldview. LLM outputs can vary with prompting, sampling settings, system instructions, and model updates. Our study does not prove whether a difference reflects pretraining data, fine-tuning, product design, system prompts, or ordinary run-to-run variation. Most likely, the variations reflect all the above. The narrower claim that under the same structured policy-analysis task, different models produced meaningfully different distributions of attention across policy dimensions remains important.
The study used 91 model policies, expert-informed rubrics, and computational validation, then tested the results against 883 additional AI governance documents. Commercial models received identical rubrics and prompt structures, and the pattern of concentrated versus distributed scoring held across both datasets. That consistency is what distinguishes systematic behavioral difference from prompt sensitivity or run-to-run variance.
The pattern held across the full dataset. Model choice shapes what a policy appears to be about. In nearly two-thirds of cases, Grok was far more likely to collapse a bill into one dominant category without identifying secondary policy dimensions. In statistical terms, Grok concentrates more than 70 percent of its analytical weight on a single policy dimension per bill. Over a third of the time, it assigned a single dimension more than 80 percent of the total weight. ChatGPT and Claude were more than twice as likely to recognize that a given policy pursues multiple goals at once.
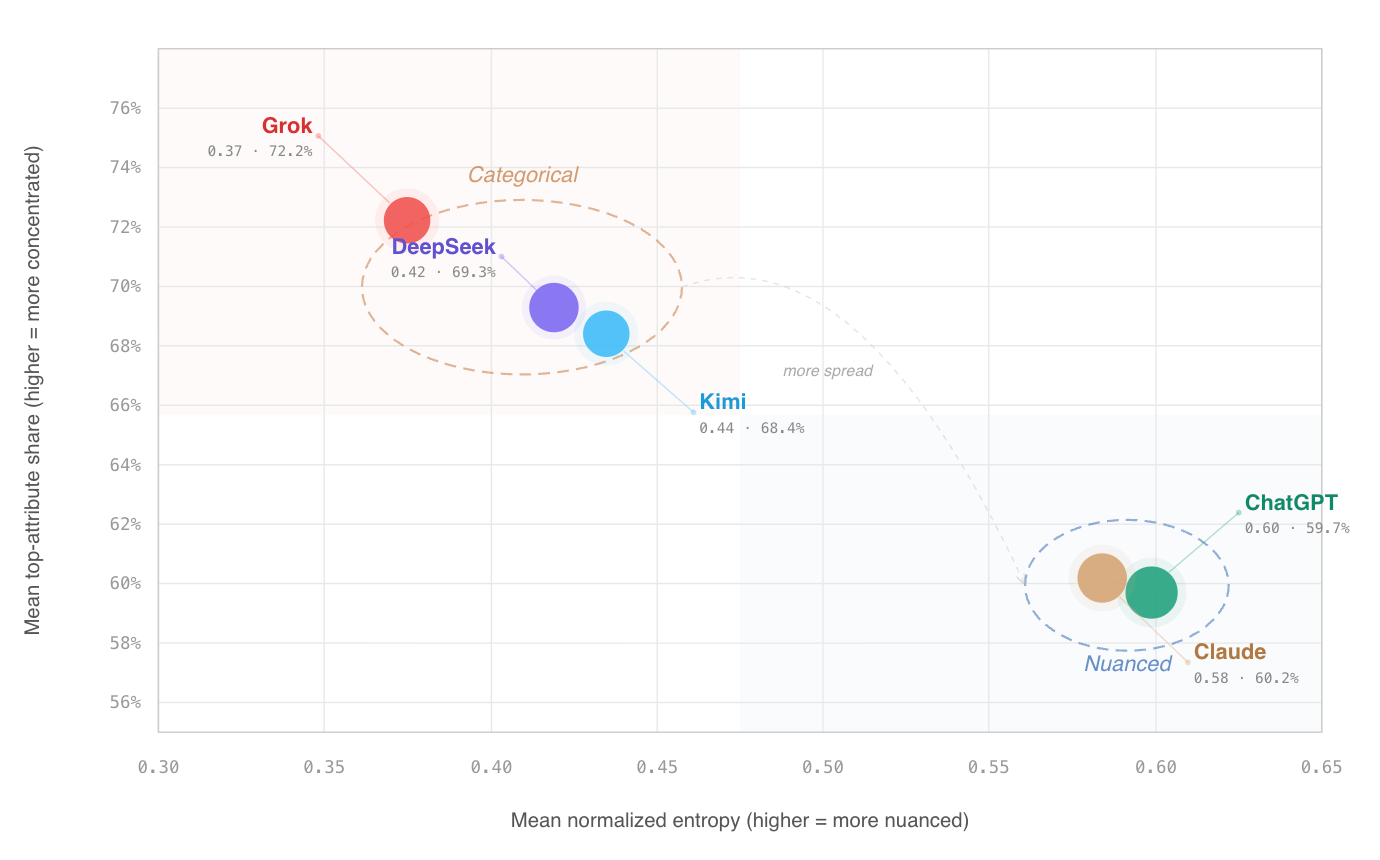
Figure: Commercial LLMs differ in how much policy complexity they capture. Source
The same pattern appeared beyond US vendors: Two Chinese models, DeepSeek and Kimi, also tended to assign hard zeros to dimensions they treated as irrelevant, suggesting that model-to-model variation is not limited to one company or country. In this sense, the tested Chinese models behaved similarly to Grok.
The models’ behavioral signatures could also change over time as they get updated. The divergences we document today could narrow or, just as easily, deepen. That potential instability argues against treating any vendor as a solid analytical baseline and indicates that version updates within a single vendor's product can shift behavior. Besides vendor choice, agencies should invest in model version documentation and behavioral testing as part of the procurement process.
Protests like the one outside OpenAI’s offices may continue, even if in different forms and at different venues. They reflect a larger argument over how the Pentagon should use AI in high-stakes situations. That is an important debate. But for the many less dramatic government uses of these systems, there is a more practical, immediate lesson. Agencies should document which model they used, which version, how they are prompting it, and what validation, if any, was performed. For routine tasks, small differences may not matter. For policy analysis, enforcement, benefits, immigration, defense procurement, or other high-impact uses, they can.
As the government's use of AI increases, agencies should document what their AI systems are more likely to see and what they may miss.
Authors




