Addressing Regulatory Arbitrage in the AI Supply Chain
Amaia Aguilar / Jun 16, 2026This post is part of a series of student essays produced in collaboration with the Berkman Klein Center for Internet & Society at Harvard University. Read more in the series here.
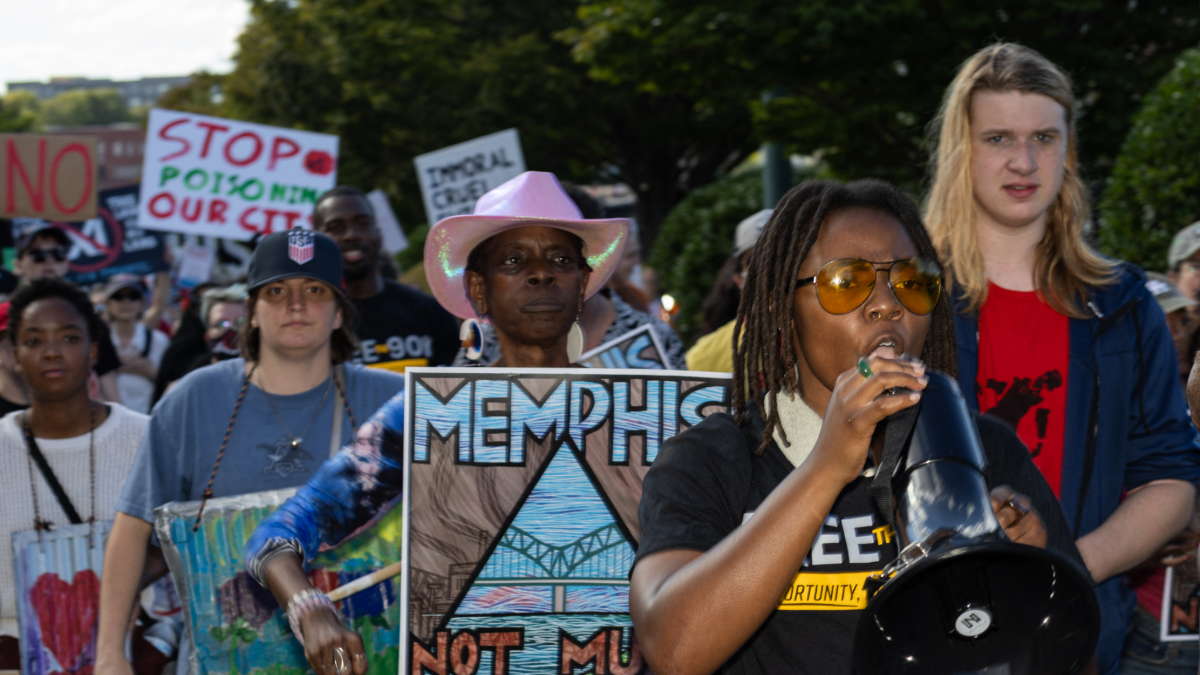
Protesters march through downtown Memphis, Tennessee, carrying signs opposing Elon Musk and xAI during the "Get Out of Memphis" demonstration on October 4, 2025. (Photo by AUSTIN JOHNSON/AFP via Getty Images)
Last year, my phone's photo album image classifier sorted me into three people: one before my transition, one during, and one after. While my face stayed the same, the algorithm apparently failed to understand my fluid identity. It would appear that people like me were missing from the training data, or perhaps simply that no one designing the system stopped to ask how we want to be represented.
This failure of recognition extends far beyond my personal experience. It is symptomatic of a major gap in protection and representation throughout entire artificial intelligence supply chains. We see it in Kenyan content moderators earning $2 an hour, denied basic labor protections while absorbing the internet's most traumatic content. We see it in Boxtown, a historically Black neighborhood in South Memphis with cancer risk quadruple the national average that is now enduring pollution from gas turbines powering a neighboring supercomputer. The populations most harmed by AI consistently have the least agency over its development, creation, and deployment.
These realities all point to the power of regulatory arbitrage. Reminiscent of the decade-long battle to regulate e-cigarettes, AI companies exploit legal gray areas to cause familiar harms through new mechanisms, all while evading existing legal protections in place. AI repackages the systemic issues marginalized communities have fought so hard against: bias, labor exploitation, and environmental racism. And deliver it through something new: algorithms, micro-task platforms, and data centers. Nevertheless the core harms remain the same.
The data that sees you, and doesn’t
When prompting a generative AI to show a transgender woman, the result in my experience is almost always a caricature. When I entered such a prompt recently, an image of a white, young barista appeared. This output was created by images assembled from the most dominant patterns in the training data available, regardless of inherent bias. Conversely, when I try to self-identify within prompts, terms like "Latina transgender woman" often trigger content filters. I end up being simultaneously erased and censored.
Marginalized populations remain highly skeptical of AI, and the results of this technology reflects this erasure. A 2019 study found that facial analysis tools from Amazon, IBM, Microsoft, and Clarifai accurately identified transgender women only 87.3% of the time, compared to 97.6% for cisgender women. For transgender men, the gap widened to 70.5% versus 98.3%. The industry claims accuracy has improved since, but 94.8% of research on automated gender recognition still treats gender as binary and 72.4% as immutable. The architecture hasn't changed; the bias persists and has just stopped being measured. Furthermore, February 2026 research demonstrates that large language models (LLMs) actively direct transgender patients toward STI and mental health services, while routing cisgender patients services like gynecology and breast care.
But a simple demand for inclusion is not enough. Transgender communities are underrepresented in everyday datasets but vastly overrepresented in sensationalized contexts like news coverage, pornography, and pathologizing content on social media. When advocates push for just inclusion, they face a double-edged sword. In jurisdictions that criminalize trans identities, comprehensive datasets easily become weapons for state surveillance and without it might perpetuate overly sensationalized ideals. Inclusion without explicit, granular consent is not equity. It is a new method of data extraction. When an algorithm eventually denies someone healthcare or housing, existing anti-discrimination frameworks fail. These regulations, having been designed for human accountability, can’t answer whether the liability lies with the developer, the deployer, or the dataset.
The workers behind the algorithms
Growing up Salvadoran in the United States, I learned early how wealthy nations offshore extractive practices to communities, often the Global South, with fewer legal protections, like textiles stitched in maquiladoras. The AI supply chain operates on this exact logic, merely substituting sweatshops for laptops.
On micro-task platforms like Remotasks, owned by Scale AI and valued at over $25 billion, Kenyan data workers earn $1.50 to $2 per hour labeling images, moderating content, and fine-tuning models, while US workers may earn as much as $15 or more for identical work. By categorizing international data workers as independent contractors rather than employees, AI companies can aggressively bypass minimum wage floors, workplace safety standards, and collective bargaining rights. An employment classification loophole enables this disparity.
The psychological toll for this type of labor is heavily documented. A 2025 Equidem survey identified 60 severe incidents of psychological harm, including PTSD and substance dependence, among a sample of just 76 data workers across Colombia, Ghana, and Kenya. These moderators assess graphic violence and child sexual abuse material in 50-second windows on contracts as short as five days. Yet, these workers are not waiting for regulators. From investigations in Colombia to 97 Kenyan data labelers petitioning the former US president, resistance is growing. The African Content Moderators Union and Kenya's Data Labelers Association are already building cross-border momentum, moving faster than the regulatory frameworks designed to protect them.
From redlining to datacenters
As a Latina raised in Reno, Nevada, surrounded by the legacy of redlining and rental covenants, I learned that racist history dictates which communities receive investment and which receive pollution. Today, Boxtown, a South Memphis neighborhood founded by formerly enslaved people, inherits that unfortunate logic.
To power its Colossus supercomputer, xAI installed 35 methane gas turbines without air quality permits in Boxtown, a community already burdened by pollution from an oil refinery and a steel mill. A Harvard-led study projects that adding 41 permanent turbines would result in up to $44 million annually in health damages. These negative externalities are concentrated almost entirely in the Black neighborhoods surrounding the facility.
Even as community pushback in Memphis forced xAI to seek permits for some of its turbines, the company expanded across the state line into Southaven, Mississippi, where regulators of the state’s Department of Environmental Quality initially classified xAI's turbines as "temporary mobile engines," exempting them from standard permitting. xAI installed as many as 27 additional unpermitted turbines in Southaven. Environmental groups argue that the EPA's January 2026 turbine rule confirms these turbines require permits, though Mississippi regulators dispute that reading. The NAACP and Southern Environmental Law Center have filed suit under the Clean Air Act. The same systems that erase my identity run on servers powered by turbines that poison Black neighborhoods, emitting nitrogen oxides and particulate matter that the Clean Air Act was explicitly written to regulate. This is regulatory arbitrage in action.
Reclassification, not reinvention
The transgender individual erased by training data, the Kenyan worker moderating that data for $2 an hour, and the Black neighborhood choking on the emissions required to process the data are all fundamentally linked. They are all victims of old harms delivered through novel, unregulated mechanisms devoid of consent.
Closing these gaps doesn’t require inventing all-new regulatory frameworks. It requires aggressively reclassifying these harms under existing statutory authorities. Just as the Food and Drug Administration (FDA) closed the e-cigarette loophole by recognizing the delivery was new but the addiction was old, policymakers must systematically apply existing legal tools to AI infrastructure.
Business leaders will argue that strict classification slows progress. But extracting unregulated labor and unpermitted emissions is not innovation; it is simply shifting the true cost of development onto communities with the least power to refuse it.
Three specific reclassifications are required immediately:
- Environmental enforcement: Data center turbines must be strictly classified as stationary sources under the Clean Air Act. Communities should not be forced to file federal lawsuits just to secure the right to breathe unpolluted air.
- Labor protections: US regulators must hold domestic tech companies accountable for their offshore digital supply chains. The EU's Platform Work Directive, mandated for 2026, offers a blueprint for how U.S. federal guidelines could reclassify these international contractors as employees to close the offshore loophole.
- Data sovereignty: Consent-based data governance must be established for biometric and identity data. Pulling from the CARE Principles for Indigenous Data Governance, vulnerable populations must have the right to free, prior, and informed consent before their identities are ingested into foundational models.
This pattern of extractive regulatory arbitrage will not end with AI. It will happen with every subsequent technological wave unless a strict precedent is set now. AI's gray areas are currently hardening into permanent physical and digital infrastructure. The harms are not new, and neither are the tools to stop them.
Read other aticles in this series
Authors

